11.1 迁移学习【斯坦福21秋季:实用机器学习中文版】
迁移学习的出发点
 -
在一个任务上学习到的知识,可以在另外一个地方用到
-
在一个任务上学习到的知识,可以在另外一个地方用到
- 因为训练要花钱,还要搞数据集
途径
训练好的模型做成特征抽取的模块,得到特征干别的事情,比如作为另外一个模型的输入
在相关的任务上训练一个模型,在另外一个任务上直接用,例如GPT系列
在训练好的模型上,针对新的任务进行微调(本节内容)
相关领域
半监督学习
极端情况下,新的任务,不给标记;或者只给几张有标记
多任务学习,每一个任务都有自己的数据但不是很够,但任务之间又有相关性
转移知识
 -
有很多大规模的标好的数据集,尤其是图片分类任务上(因为标记很容易)
-
有很多大规模的标好的数据集,尤其是图片分类任务上(因为标记很容易)
计算机视觉的迁移学习里面,存在很多效果比较好的模型,希望把这些模型的知识拓展到自己的任务上去
- 刚开始进行任务的时候可能不会投入太多,看能不能利用别人在标记好的、比自己的数据集大10倍,100倍的数据集上面学到的一些东西迁移过来,试试效果
预训练模型
 -
用的最多的迁移学习的方法
-
用的最多的迁移学习的方法
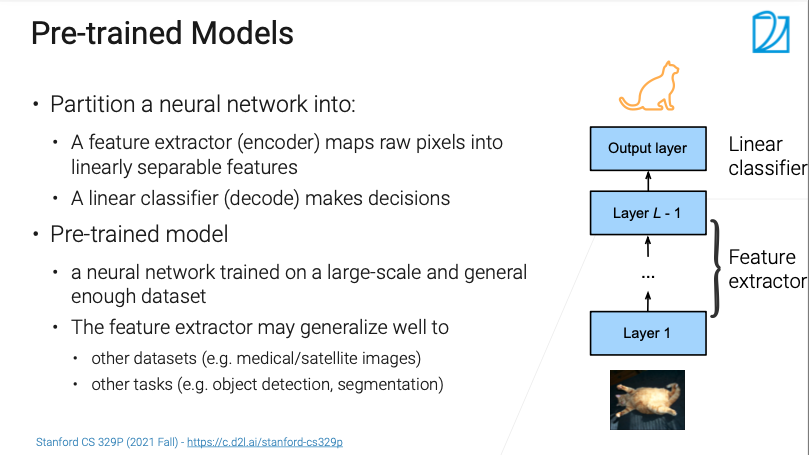
一般来说,一个神经网络大概分为两块
编码器
- 可以认为是特征提取器
- 将像素转化为在语义空间里面线性可分的一些特征(浅表示)
解码器
- 可能就是个线性层
- 把编码器的输出映射为最终结果,做决策
例如
- 给个猫的图片
- 可以认为除了最后一层之外的,都是编码器
- 最后一层把语义特征(如1024的特征向量),转化为语义空间内的表示
- 也可以认为最后几层都是解码器,剩下的是编码器
预训练模型
在比较大的数据集上训练好的一个模型
训练的数据集大,可以认为其有一定的泛化能力
- 泛化能力指,放到别的任务或者数据集上,多多少少也是能帮点忙
- 虽然目标任务可能不会对猫感兴趣,但是编码器部分多多少少学会了点怎么样去处理像素的信息
- 在ImageNet上训练的模型,能对其他任务的图片做特征提取,总比从随机开始好
Fine-Tune技巧
 -
通常认为,在深度学习中微调能够带来最好的效果
-
通常认为,在深度学习中微调能够带来最好的效果
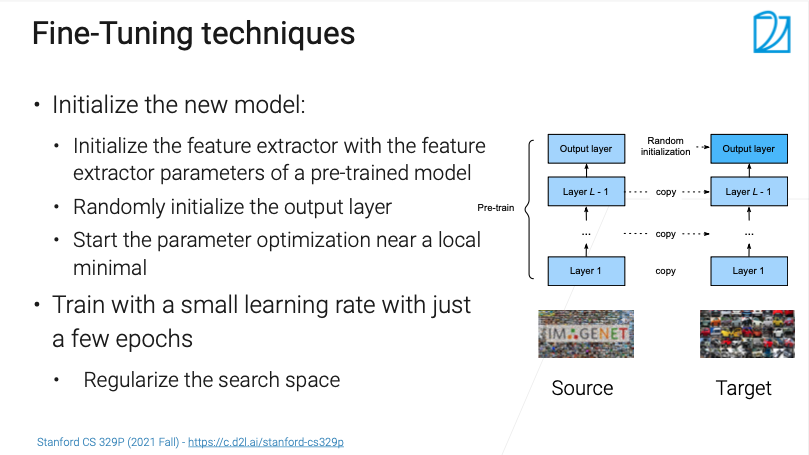
在新的任务上面,构建一个新的模型,其架构要与预训练模型一样
- 如一个在ImageNet上训练好的ResNet 50模型
- 在新的任务上面,也要用一个ResNet 50模型(可以先找找在当前任务的特定架构上是不是有比较好的预训练模型)
初始化模型
新模型的特征提取器(编码器)的权重直接从预训练模型得到
解码器的权重随机初始化
- 不同任务的语义空间不同
例如图中右侧的例子
在限制搜索空间,进行训练
因为之前效果已经比较好了,已经在最优解附近了
要把学习率调的小
- 例如正常是0.1,现在要用1e-3
epoch数要小
例如
- 不做特别的限制的话,不管是fine-tune还是随机初始化整个网络,在足够长的时间下,网络都会达到一个特定的程度,但这个程度并非是最佳状态
- 泛化误差和训练误差是不一样的
- 在数据集不大且网络足够复杂的情况下,网络是可以记住整个数据集的
- 训练误差最低的时候,泛化误差不一定更好
- 在完全拟合自己的数据和保留在大数据集上的泛化能力之间,做一个权衡
冻结底层网络
 -
限制搜索空间的另一种方法
-
限制搜索空间的另一种方法
因为神经网络有个比较层次化的学习过程
在最底层学到一些底层的特征的表示,像素底层特征,学习到的纹理是什么形状、颜色的知识
- 如一个圆圈,图形的边
层数越来越高的时候,多多少少会学到一些更大,更全局的东西,更加跟语义相关
最下面的层在微调的时候不动
- 例如第0层学习率为0,第1层为1e-8,第二层为1e-7
- 通常做法,固定住最下面一些层,往上面一些层学习率为1e-3,再往上是1e-1
需要固定多少层是需要调的
- 若目标任务和预训练模型之间差比较大的话,需要多训练一些层
- 差异小的话,可以固定更多层,极端情况下甚至可以只允许最后一层进行训练
在哪儿找与训练模型
 -
在微调的时候怎么样找到一个与训练模型,很重要
-
在微调的时候怎么样找到一个与训练模型,很重要
首先有没有
- 例如要注重latency的话,找个训练好的MobileNet
其次是考虑在什么样的大数据集上
- 例如是在ImageNet上训练好的
各种各样的Hub
Timm的Hub
Fine-Tune应用
 -
使用在大数据集预训练好的模型,Fine-Tune到自己的任务上,是过去七八年至现在,在CV方面都是一个主流方法
-
使用在大数据集预训练好的模型,Fine-Tune到自己的任务上,是过去七八年至现在,在CV方面都是一个主流方法
- 目标检测/分割----图片相似但目标不同
- 医学/卫星图像识别----任务相同但图像不同微调加速了收敛
- 开始的点不是随机初始化的点,而是比较靠近目标的点
不一定提升精度
- 预训练的数据集和目标数据集比较像的时候,一般结果会比只在目标数据集上训练好
- 有时候直接在目标数据集上训练时也会得到一个相似的结果,特别是在目标数据集比较大的情况下
- 通常不会让精度变得更低,So why not?
总结
 -
通常会在比较大的数据集上训练预训练好的模型
-
通常会在比较大的数据集上训练预训练好的模型
在新的任务上,初始化一个编码器部分的权重和预训练模型权重一样的模型,解码器权重随机初始化
微调通常来说加速收敛,有时会提升精度,但不会使得精度变差
11.1 迁移学习【斯坦福21秋季:实用机器学习中文版】
