代码随想录算法训练营第6天 | 242.有效的字母异位词,349.两个数组的交集,202.快乐数,1.两数之和
没第5天?因为第5天是周日,放个假。
哈希表理论基础
什么是哈希表
哈希表就是根据数据的关键码来对数据进行直接访问的数据结构。例如数组其实就是一个哈希表,可以根据数据的索引来直接访问对应位置的数据。
哈希表主要用来解决快速判断一个元素是否出现在一个集合中。这里的快速判断是指要通过\(O(1)\)的时间复杂度来判断,而并非像遍历数组那样的\(O(n)\)的时间复杂度。
哈希函数
通过一定的计算方法,将要存储的数据转化出来对应的哈希表上的索引的函数,为哈希函数。
例如,将学生的姓名通过哈希函数计算出数值,再将该学生的姓名存放在哈希表上的对应位置。
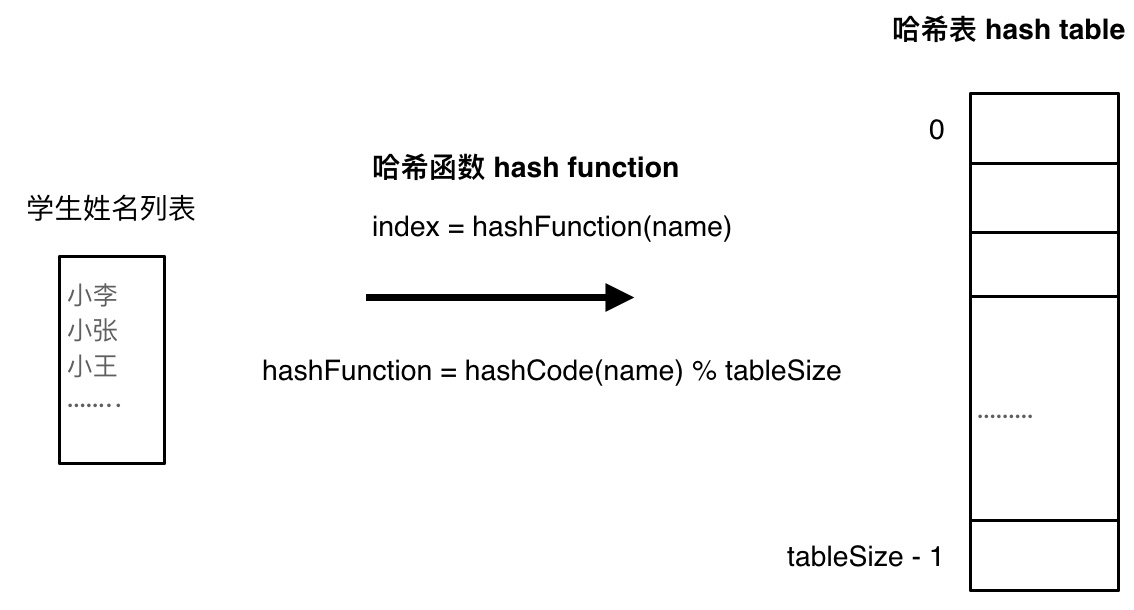
如果哈希函数的设计不足以完全达到对不同的数据产生一定产生不同的哈希值(例如哈希函数为 x % 10时,数据11和数据21的哈希值都是1),就会发生哈希碰撞。
哈希碰撞
在下面这个图中,两个不同的数据,通过哈希函数计算出来的哈希值是相同的。
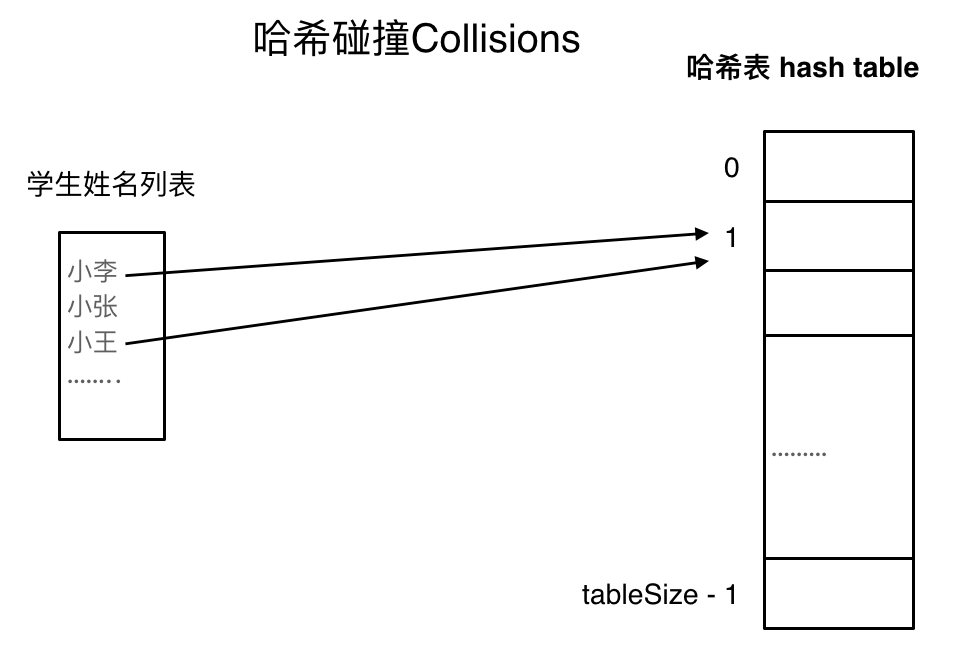
解决哈希碰撞主要有两种方法:
- 拉链法
哈希表表内实际上存储的是一个一个(警撅)链表的表头指针,将发生哈希碰撞的数据按照插入的先后顺序,存放在对应位置的链表上。如图所示。
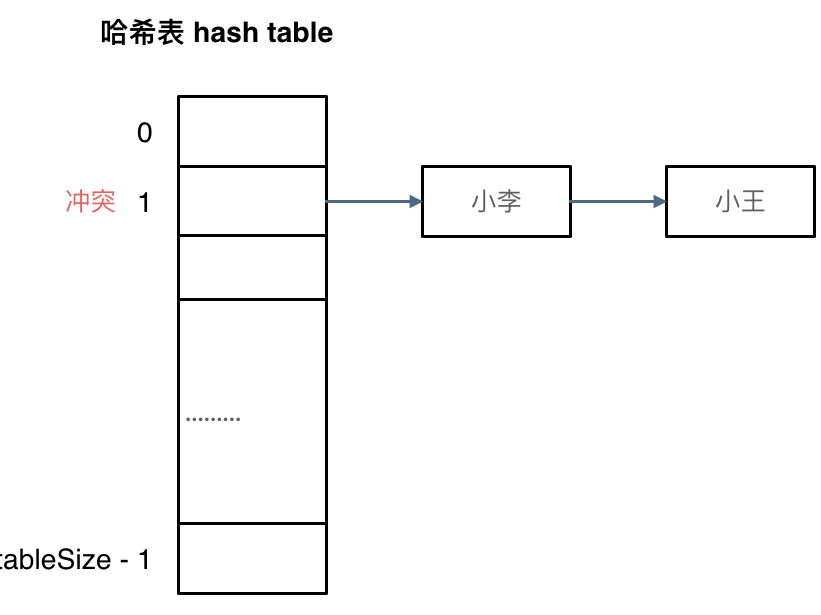
- 线性探测法
该方法的思想是,在遭遇到碰撞时,从哈希值所指的位置开始,线性向后依次探测出一个空位置,并将数据存放至该空位置。
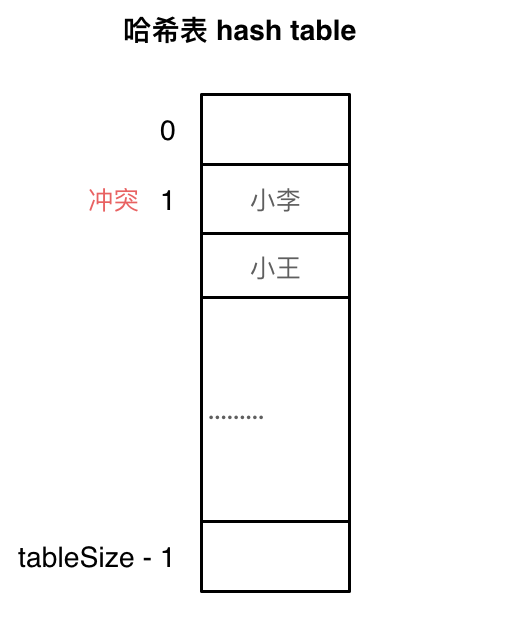
但是单纯的线性探测,会使得哈希值相同的数据聚集在同一个区域,此时一个改进的方法就是将“依次探测空位置”变为“按照一定的计算方法向后探测位置”,如将向后探测位置的步数从每次加1改为向后探测\(1^2, 2^2, ...\)。
- 再哈希
准备多个哈希函数,在出现哈希碰撞时,使用下一个哈希函数进行计算,直至哈希函数不再冲突。
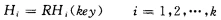 其中\(RH_i\)为不同的哈希函数。
其中\(RH_i\)为不同的哈希函数。
常见的三种哈希结构
- 数组
- set--集合
- map--映射
数组作为哈希结构在上文中有提到。
set在C++主要有下面三种数据结构,将代码随想录的表格抄过来,如下表所示:
| 数据结构 | 底层实现 | 有序 | 可以重复 | 可以更改数值 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| std::set | 红黑树 | Y | N | N | \(O(logn)\) | \(O(logn)\) |
| std::multiset | 红黑树 | Y | Y | N | \(O(logn)\) | \(O(logn)\) |
| std::unordered_set | 哈希表 | N | N | N | \(O(1)\) | \(O(1)\) |
红黑树是一种平衡二叉搜索树,所以key是有序的,但key不能修改,只能对数据进行删除和增加。
C++中,集合的调用形式为:
1 | |
映射,顾名思义,就是将一个值映射到另外一个值上面,形成一定的对应关系。
map在C++中主要有以下三种数据结构,将代码随想录的表格抄过来,如下表所示:
| 数据结构 | 底层实现 | 有序 | 可以重复 | 可以更改数值 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| std::map | 红黑树 | Y(Key) | N | N | \(O(logn)\) | \(O(logn)\) |
| std::multimap | 红黑树 | Y(key) | Y | N | \(O(logn)\) | \(O(logn)\) |
| std::unordered_map | 哈希表 | N(Key) | N | N | \(O(1)\) | \(O(1)\) |
同上,multimap和map中的key是有序的且无法修改。
C++中,映射的调用形式为:
1 | |
使用集合来解决哈希问题时,优先使用unordered_set,因为其查询效率和增删效率都是最优的。
242.有效的字母异位词
题目
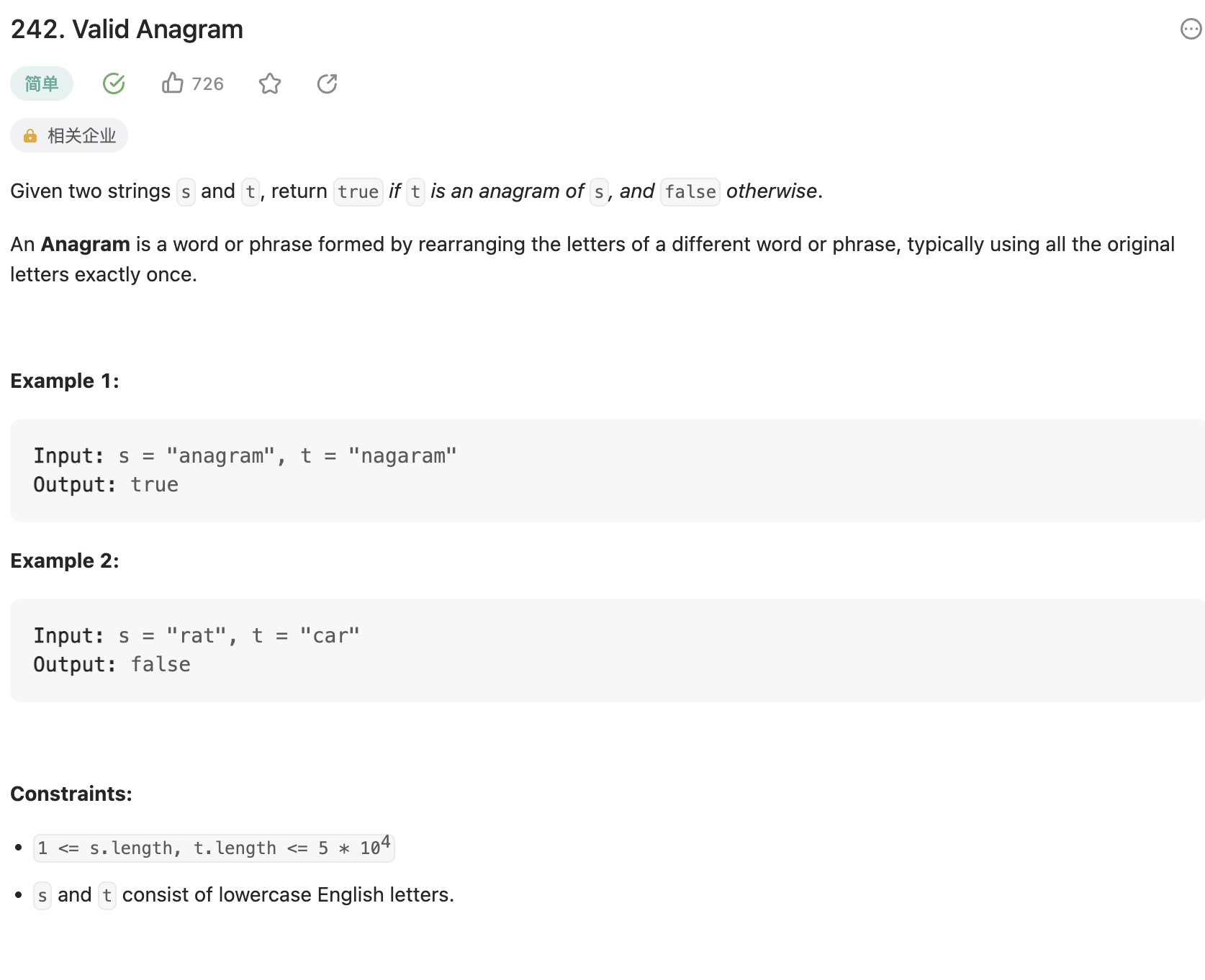
给定两个字符串,判断这两个字符串是否是异位词。
自己的想法
异位词的其实就是同样的一组字母,进行不同的排列而形成的单词。特点有:
- 出现的字符相同
- 每个字符的出现次数相同
那在这里其实就可以使用映射关系,来存储26个字母中每个字母的出现的次数。可以使用数组,也可以使用map。
解法
1 | |
该解法时间复杂度为\(O(n)\),空间复杂度为\(O(1)\)。
349. 两个数组的交集
题目
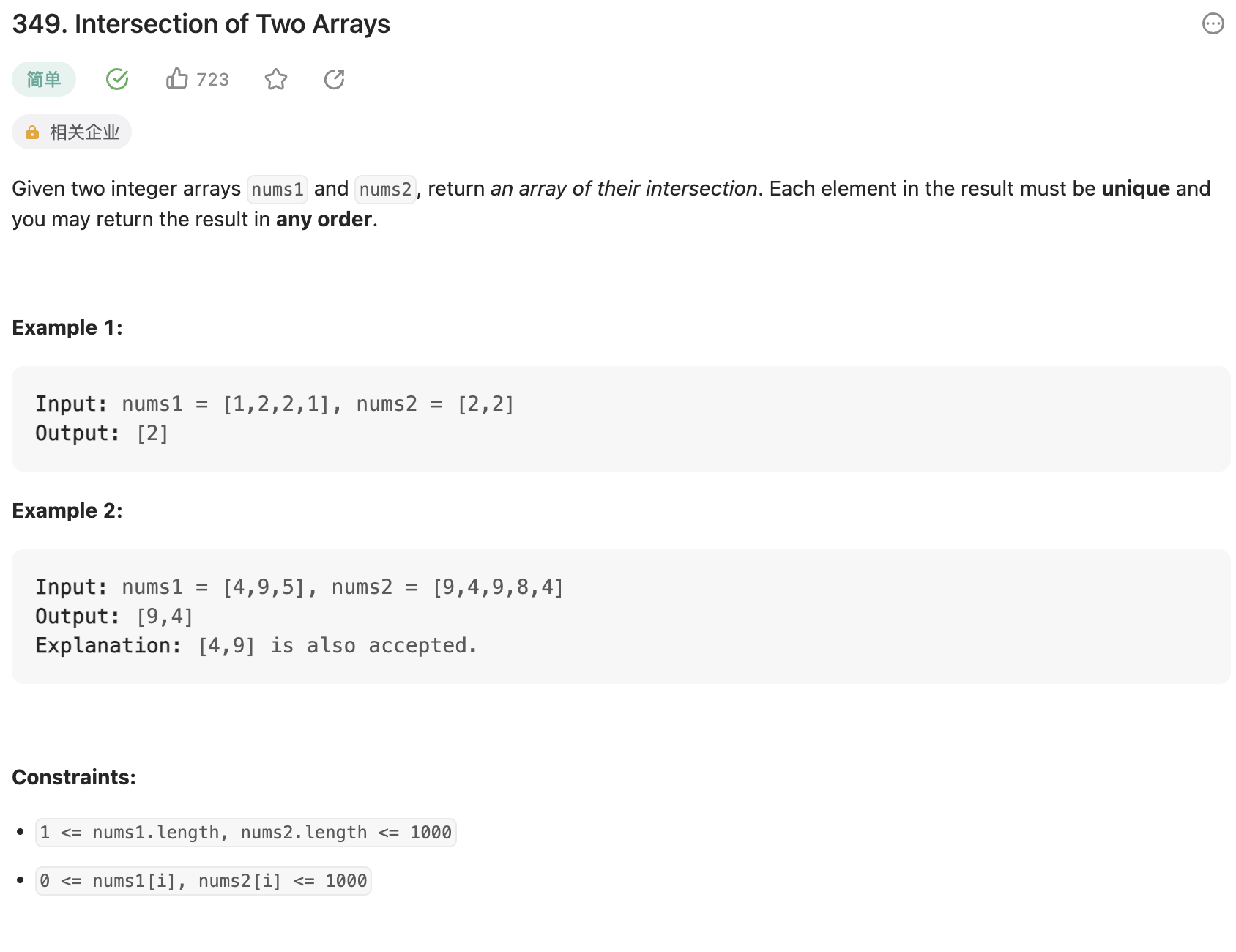
给定两个数组,输出它们的交集。
自己的想法
集合么,将一个数组转为一个集合,然后遍历另外一个数组,依次判断第二个数组中的值是否存在于集合中,若存在,则将该数插入到结果集合中。
解法
1 | |
unordered_set的查询和增删效率都是\(O(1)\),故生成集合的过程耗费时间为\(O(n)\),遍历并判断是否存在以及插入到结果集合所耗费的时间为\(O(n)\),将结果转化为数组的时间为\(O(n)\),故时间复杂度为\(o(n)\),空间复杂度为\(o(n)\)。
202. 快乐数
题目
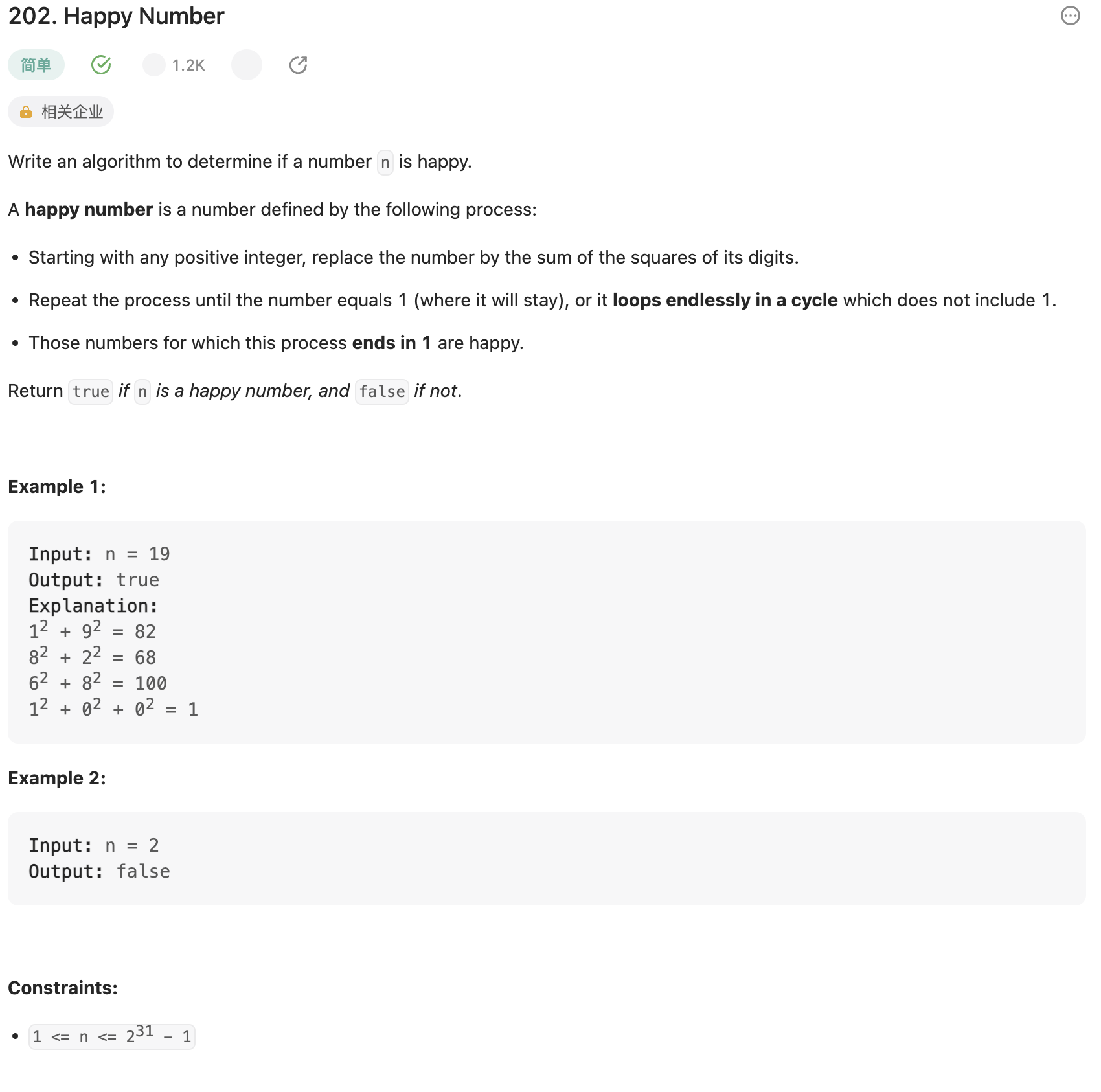
判断一个数是否为快乐数,快乐数的定义为:进行一个循环,每次循环都将这个数替换为其各位数的平方和,若最终平方和为1,则该数为快乐数;若一直无限循环,则该数不是快乐数。
自己的想法
一直无限循环的话,每次替换的数值必定会有重复的,例如给定数是2时,其替换的值依次为:4,16,37,58,89,145,42,20,4,...。是一个重复的序列。
所以我们可以使用一个集合,当替换的值不为1时,判断每次替换的值是否存在于该集合中,如果存在则说明非快乐数,否则就将该替换值加入集合当中,继续循环。
解法
1 | |
1. 两数之和
题目
给定一个数组和一个值,判断该数组中是否存在两个数且他们之和为给定值,若存在,则输出这两个值的索引。
自己的想法
暴力解法,两个for循环,根据一个数来查是否存在另外一个数
由于要输出的是两个值的索引,这个地方可以使用map来存储<值, 索引>对来解决问题。
解法一
1 | |
时间复杂度为\(O(n^2)\),空间复杂度为\(o(1)\)。
解法二
1 | |
unordered_map的查询和增删效率都是\(O(1)\),故该实现的时间复杂度为\(O(n)\),空间复杂度为\(o(n)\)。
代码随想录算法训练营第6天 | 242.有效的字母异位词,349.两个数组的交集,202.快乐数,1.两数之和
